
Algorithm implementation on an embedded system comes with some natural limitations. These limitations are due to the reduced performance of an embedded system compared to the performance of a workstation PC used to develop and test the algorithm. One way to increase the performance envelope of your embedded system to meet the needs of your algorithm is to transition your design to use a new class of heterogeneous system-on-chip (SoC).
The term heterogeneous system used here refers to embedded systems with more than one domain of processing capability, specifically, both a processing system (PS) domain and a programmable logic (PL) domain. The term is not referring to a system-on-chip (SoC) of more than one microprocessor or multiple microprocessor architectures in its PS. A key component of a heterogeneous system is that it includes a communication fabric or interface between the two processing capability domains so they directly communicate and work together. Real world examples of such a system are the Xilinx Zynq-7000 SoC and the Zynq UltraScale+ MPSoC series of SoC devices. These devices contain a FPGA that forms the PL domain and interfaces together with on-chip ARM Cortex-A series application processing cores.
For software engineers familiar with working with a typical embedded microprocessor, it may seem daunting to get started with a heterogeneous embedded system. However, there are tools available that ease the transition. Additionally, selecting this kind of SoC for use in your embedded system design has advantages over a traditional microprocessor or even more complicated multicore SoCs. Adding the PL does not remove functionality from the PS that software engineers are already comfortable and familiar with programming. These additional PL resources are flexible and can powerfully augment the processing capability of the PS in a variety of ways, including expanding I/O to the PS, adding high-speed interfaces, and creating customer interfaces with external devices. The PL excels at augmenting the PS also through solving parallel algorithmic problems that prove to be difficult to solve in real time in a PS, even a PS with multi-core processing.
How does an engineer already experienced and comfortable with working in the PS domain of functional programming languages take advantage of the additional flexibility and power of the PL? The traditional method is through education and training to learn to program the PL in a hardware description language (HDL) such as Verilog or VHDL. Another way is to learn and utilize a tool (or toolchain) that enables the engineer to take their design solution written for PS and transfer it (either in whole or in part) to the PL, without needing to learn to program in HDL.
One such tool is the Vivado High Level Synthesis (HLS) tool developed by Xilinx. By leveraging the capabilities of HLS, an engineer can utilize model-based development for prototyping in their build environment or on the PS and implement the functionality of the model in PL. The advantage of this tool is that the generated IP blocks can be used as standalone IP blocks in the programmable logic of FPGA-only SoCs. The outputs are not limited to PS-PL heterogeneous applications. It enables engineers to prototype and develop in the software domain that they are experts in, and take advantage of the power of the FPGA that they discovered. It provides the same capability to transfer your algorithm or solution implementation written in C/C++language to RTL (register-transfer level) logic targeting the Xilinx PL on its Zynq-7000 and Zynq UltraScale+ devices. The logic optimization process occurs when HLS synthesizes the C model of your algorithm to RTL targeting the PL on the heterogeneous system. There are code directives (essentially guidelines for the tools’ optimization process) available to the user that allows you to guide the HLS tool’s synthesis from the C model source to the RTL bitstream programmed into the FPGA. If you are working with an existing algorithm, model in C, C++, or System C and need to implement it in FPGA custom logic only (you do not require a companion PS at this time), then HLS is a great choice of tool. However, if using HLS with a heterogeneous system, the data movers for data transfer between the PS and the PL are manually configured for performance. This can become a complicated process for complex designs with significant data transfer between the domains.
A recent innovation that simplifies the data mover configuration is the development of the Xilinx SDSoC (Software-Defined System on Chip) Development Environment, also known simply as SDSoC. SDSoC builds on the capability of HLS by using HLS to perform the C model to RTL transfer with the convenient addition of auto generated data movers. This greatly simplifies configuring the connection of the software running on the PS with the accelerated algorithm executing in the PL of the system. SDSoC also allows you to guide the data mover generation by providing a set of code directive pragmas to make specific data mover choices. The SDSoC directive pragmas enable control over the auto generated data movers to transfer efficiently between the PS and PL, though still with minimal user manual configuration effort. The code directive pragmas for RTL optimization that are available in HLS are also available in SDSoC and can be used in tandem for optimizing both the PL algorithm and the auto generated data movers.
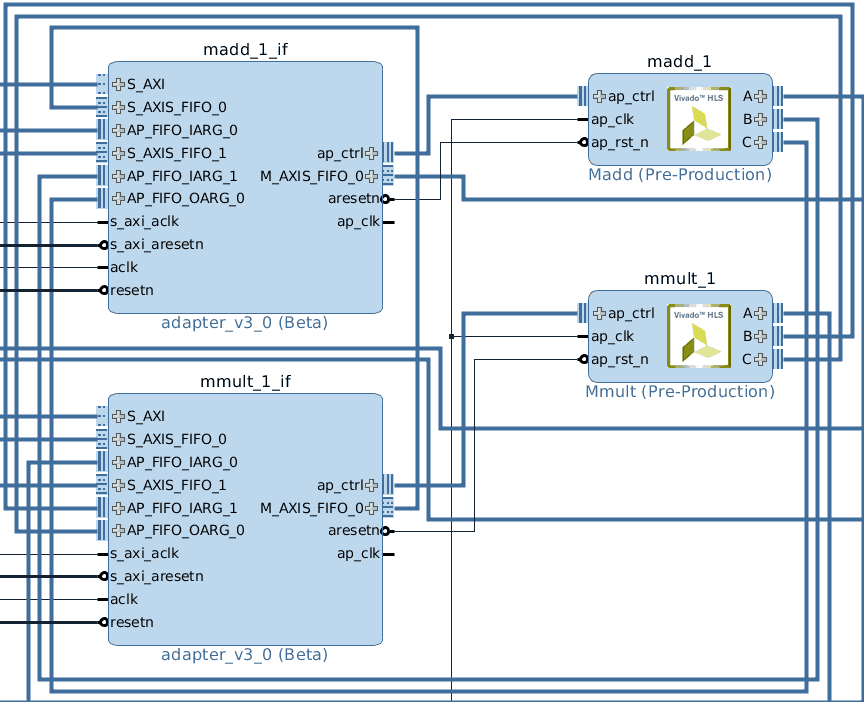
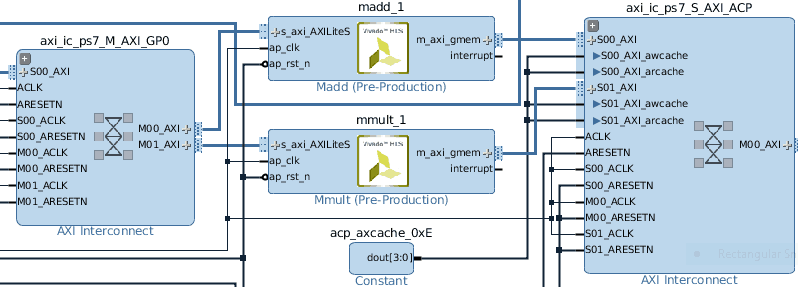
SDSoC is intended to be used only for Zynq-based heterogeneous systems. If you are looking to accelerate or offload existing algorithms to improve application performance in a heterogeneous system, the SDSoC Development Environment toolchain is the place to start. The FPGA design’s IP blocks will differ for the same code generated by SDSoC and HLS as you can see in the examples below. It is possible to disable the SDSoC auto generated data movers and only use the HLS optimizations. Demonstrated below are an IP block diagram generated with the auto configured SDSoC data movers and one without them.
These screenshots are from a Xilinx provided template project demonstrating the acceleration of a software matrix multiplication and addition algorithm, provided with the SDx installation. We used the SDx 2016.4 toolchain and targeted a Zedboard with a standalone OS configuration for this example.
Here is a screen shot of the same block but without the SDSoC Data Movers (disabled SDSoC auto generated data movers within SDSoC, by manually declaring the AXI HLS interface directives for both mmult and madd accelerated IP block.).
In order to achieve the best performance for your algorithm, be prepared to utilize and familiarize with both the SDSoC and HLS user guides and datasheets provided by Xilinx to maximize the optimization of your design. The functionality provided to you by the SDSoC is a superset of the functionality provided by HLS tool.
If you are developing and accelerating your model from first principles but want to take advantage of the flexibility of testing and proving out a software design in software first, and don’t intend to use a heterogeneous system, then using the HLS toolset straightaway is the place to start. A design started in HLS is transferable to an SDSoC, if requirements change. Alternatively, if using a heterogeneous system is possible now or in the future, it would be worthwhile to start right away with using SDSoC.
The Xilinx SDSoC Development Environment and Vivado HLS tools are both available within the Xilinx SDx Toolchain installation.
If taking advantage of these tools in your algorithm implementation process on embedded systems is interesting to you and you are looking for more information, we have a design example you can follow. We highlighted the usage of the SDx tool chain in accelerating the AES block cipher, operating in CBC and CTR modes on the Zedboard powered by Zynq-7000 SoC.
Xilinx offers labs and tutorials for further exploration. We recommend starting with Xilinx’s own UG1027 and UG1028 to get started with SDx and the SDSoC development environment.
