
When it comes to the size of your neural network, bigger isn’t always better.
Machine learning (ML) applications are helping automotive companies develop solutions for vehicle detection and systems that can identify people, objects and animals but the sheer size and scope of these systems is often prohibitive to those who need real-time response in a confined space.
There are many excellent devices available for the edge deployed ML solutions. These devices can, however, be hindered by the more rigid architectures they employ when compared to an FPGA. Many solutions also have to contend not only with the ML portion of the design, but many other tasks such as:
Other often overlooked challenges of AI/ML designs are how to define or re-define the architectural boundaries of the solution. AMD Vivado SDSoC allows software engineers to explore hardware acceleration of key modules with the clock of a mouse. Vivado DNNDK provides many utilities to explore various ML approaches and optimization techniques.
An FPGA based approach also allows you to stay on the same platform from prototype to deployment. These reasons and more are why you should explore the overall benefits of a AMD UltraScale+ SoC for your ML project.
The Deep Neural Network Development Kit from AMD further lowers the barriers to successful ML development. Initially developed by DeePhi, a Beijing-based ML start-up acquired by AMD in 2018, the DNNDK takes in neural network models generated in Caffe, TensorFlow, or MXNet, shrinks the network complexity by pruning synapses and neurons and reduces the data type of the weights from 32 bits to 8 bits.


The accuracy of the model is reduced by about 1 percent, but the resulting network is streamlined enough to fit on an FPGA with minimal porting effort, enabling embedded systems to run ML applications without being held back by computational bottlenecks.
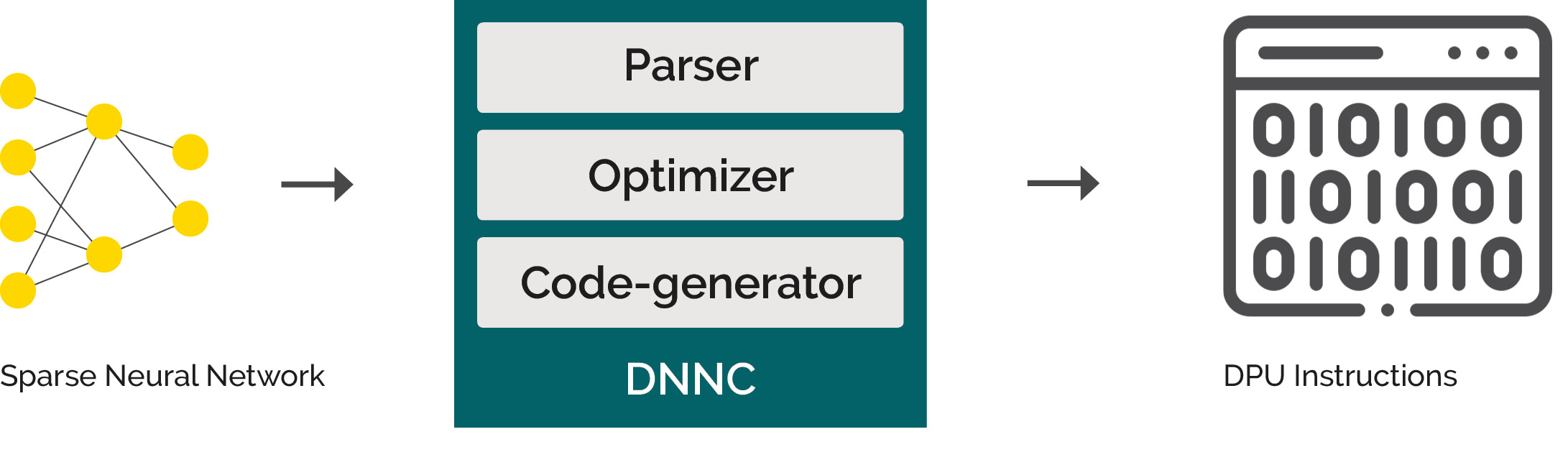
AI inference models can be successfully implemented using the DNNDK on edge devices like the AMD Zynq MPSoC, as well as cloud-based data center systems like AMD Alveo accelerator cards. The implementation process looks like this (Figure 4):

DeePhi offers example reference designs for the AMD ZCU102, ZCU104, and Ultra96 development boards, and DornerWorks can guide your company to a successful AI/ML implementation using any of them. DornerWorks’ embedded engineers David Norwood and Corrin Meyer attended the DNNDK workshop in spring 2019 and integrated this solution on MPSoC development boards alongside AMD’s own employees and FAEs.
Norwood and Meyer have experience working with neural network models on embedded systems, and are now able to build even lighter weight systems using the DNNDK.
With AI/ML applications running on the programmable FPGA logic, product developers can leverage higher throughput and lower latency than ever before, with response times less than 3ms. In the embedded space, AMD’s DNNDK is now being used help companies develop and deploy products for markets that hold to time-critical standards like IEEE 802.1 and that for Time-Sensitive Networking (TSN).
Neural network development can be complex, but you don’t have to master it on your own. Schedule a consultation with DornerWorks today and start building ML and AI applications that lead the market.
